Howdy! How can we help you?
(Tor)ブラウザ・フィンガープリンティング: イントロダクションと今後の課題
ブラウザ・フィンガープリンティング: イントロダクションと今後の課題
by gk|2019年9月4日
ピエール・ラペルドリクスによるゲスト投稿

ここ数年、ブラウザ・フィンガープリンティングと呼ばれる技術が、プライバシーにもたらすリスクのために注目を集めている。それは何なのか?どのように使われるのか?Tor Browserはそれに対して何をしているのか?このブログポストでは、これらの疑問に答える。始めよう!
ブラウザフィンガープリントとは何か
ウェブが始まった当初から、ブラウザは同じウェブページを表示したときに全く同じ動作をするわけではなかった。ある要素が不適切にレンダリングされたり、間違った位置に配置されたり、ページ全体が単に間違ったHTMLタグで壊れてしまったり。この問題を解決するために、ブラウザは「ユーザーエージェント」ヘッダーを含むようになった。これは、使用されているブラウザをサーバーに知らせるもので、サーバーはデバイスに最適化されたページを送ることができる。90年代には、”Best on IE “や “Optimized for Netscape “といった悪名高い時代が始まった。
2019年、ユーザー・エージェント・ヘッダーはまだ残っているが、それ以来多くの変化があった。プラットフォームとしてのウェブの機能は格段に豊かになった。音楽を聴いたり、ビデオを見たり、リアルタイムでコミュニケーションをとったり、仮想現実に没頭したりすることができる。また、タブレット、スマートフォン、ノートパソコンなど、非常に多様なデバイスを使って接続することができる。あらゆるデバイスや使い方に最適化された体験を提供するためには、サーバーと設定情報を共有する必要がある。「これが私のタイムゾーンで、NBAファイナルの正確な開始時間を知ることができる。これが私のプラットフォームで、ウェブサイトは私が興味を持っているソフトウェアの正しいバージョンを提供することができる。これが私のグラフィックカードのモデルで、ブラウザでプレイしているゲームが私のためにグラフィック設定を選んでくれる。
これらすべてが、私たちに快適なブラウジング体験を可能にし、ウェブを真に美しいプラットフォームにしている。しかし、ユーザー体験を最適化するために自由に利用できるこれらの情報はすべて、ブラウザのフィンガープリントを構築するために収集することができる。
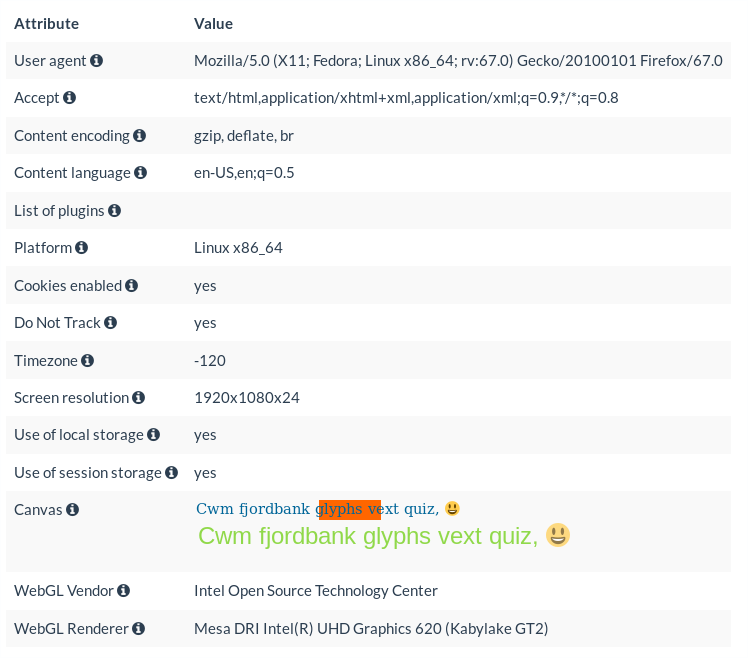
Firefoxフィンガープリント
図1:Firefox 67を実行しているLinuxラップトップからのブラウザフィンガープリントの例
図1では、私のLinuxラップトップから採取したブラウザフィンガープリントを見ることができる。フィンガープリントの情報は受け取ったHTTPヘッダーでHTTP経由で、そして小さなスクリプトを実行することでJavaScript経由で収集された。この「user-agent」は、ユーザーがFedora LinuxディストリビューションでFirefoxバージョン67を使っていたことを示している。content-language “ヘッダーは、ユーザーが “US “バリアントで英語のページを受け取ることを望んでいることを示している。タイムゾーンの「-120」は、GMT+2時間を指している。最後に、WebGLレンダラーはデバイスのCPUに関する情報を提供する。ここでは、ラップトップはKaby Lake RefreshマイクロアーキテクチャのインテルCPUを使用している。
この例は、フィンガープリントで収集できるものの一端であり、正確なリストは、新しいAPIが導入され、他のAPIが修正されるにつれて、時間とともに変化している。自分のブラウザのフィンガープリントを見たい方は、ぜひAmIUnique.orgを訪れてほしい。これは、ブラウザのフィンガープリントを研究するために私が2014年に立ち上げたウェブサイトである。100万人以上の訪問者から収集したデータにより、その内部構造に関する貴重な洞察を得ることができ、私たちはこの領域の研究を推し進めた。
なぜフィンガープリンティングがオンラインプライバシーを脅かすのか?
それは極めて単純である。まず、これらの情報を収集するために許可を求める必要がない。ブラウザで実行されているスクリプトはすべて、あなたがそれについて知ることなく、あなたのデバイスのフィンガープリントを密かに構築することができる。第二に、ブラウザのフィンガープリントの属性の1つがユニークな場合、またはいくつかの属性の組み合わせがユニークな場合、あなたのデバイスを特定し、オンラインで追跡することができる。その場合、ID入りのクッキーは必要なく、フィンガープリントだけで十分だ。願わくば、次のセクションで見るように、ユーザがフィンガープリントにユニークな値を持つことを防ぎ、その結果トラッキングを避けるために、多くの進歩がなされたことを。
Tor + フィンガープリント
Tor Browserは、” browser fingerprinting “という用語が作られる前の2007年の段階で、フィンガープリンティングがもたらす問題に対処した最初のブラウザだった。2007年3月、Torボタンの変更履歴には、Date ObjectのタイムゾーンをマスクするJavascriptフッキングが含まれていた。
結局のところ、Torの開発者が選択したアプローチは単純である。どんなデバイスやオペレーティングシステムを使っていても、あなたのブラウザフィンガープリントはTor Browserを実行しているどのデバイスとも同じであるべきなのだ(詳細はTorのデザインドキュメントにある)。
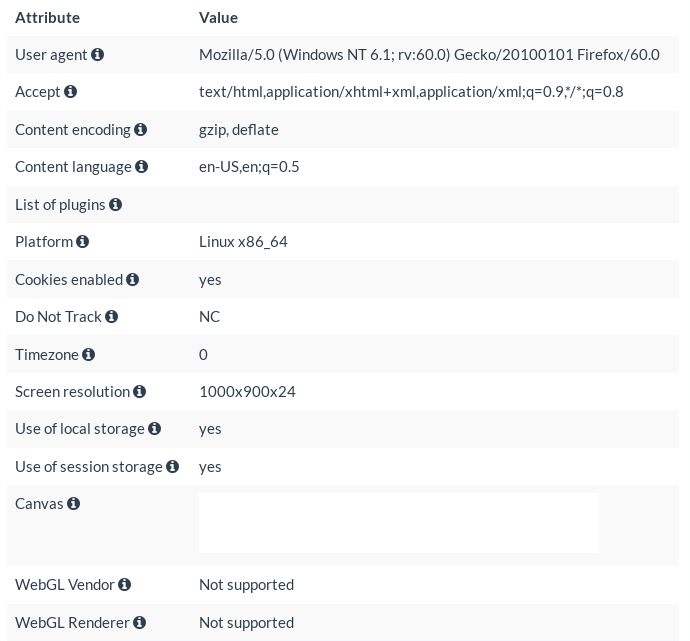
Torブラウザのフィンガープリント
図2: Tor Browser 8.5.3が動作するLinuxラップトップのブラウザフィンガープリントの例
図2で、Torブラウザのバージョン8.5.3を実行している私のLinuxマシンのフィンガープリントを見つけることができる。
Firefoxのものと比較すると、顕著な違いが見られる。まず、Tor BrowserがどのOSで動作していても、常に以下のユーザーエージェントがある:
Mozilla/5.0 (Windows NT 6.1; rv:60.0) Gecko/20100101 Firefox/60.0
Windowsは地球上で最も普及しているOSであるため、TBBはWindowsマシン上で動作していると主張することで、基盤となるOSを隠している。Firefox 60は、TBBのベースとなっているESRバージョンを指す。
その他の目に見える変更としては、プラットフォーム、タイムゾーン、画面解像度がある。
また、あなたはなぜブラウザのウィンドウを最大化すると次のようなメッセージが表示されるのか不思議に思ったかもしれない(図3参照): 「Tor Browserを最大化すると、ウェブサイトがあなたのモニターサイズを判断することができ、あなたを追跡するのに使われる可能性がある。私たちはTor Browserウィンドウを元のデフォルトサイズのままにしておくことを推奨する。」
これはフィンガープリンティングのためである。ユーザーはそれぞれ異なるスクリーンサイズを持っているので、違いが観察できないようにする1つの方法は、全員が同じウィンドウサイズを使用することである。ブラウザウィンドウを最大化すると、この特定の解像度でTor Browserを使っているのはあなただけということになり、オンライン上でより高い識別リスクが生じる。

Torブラウザの警告1Torブラウザの警告2
図3: ブラウザウィンドウを最大化したときのTorブラウザからの警告
フードの下でユーザー間の違いを減らすために、さらに多くの修正が行われている。フォントとキャンバスのフィンガープリンティングを減らすために、デフォルトのフォールバックフォントが導入された。レンダリングのステルス収集を防ぐため、WebGLとCanvas APIはデフォルトでブロックされている。performance.nowのような関数も、マイクロアーキテクチャ攻撃に使用される可能性のあるブラウザのタイミング操作を防ぐために修正された。舞台裏でTorチームが行った努力のすべてを見たい場合は、バグトラッカーのフィンガープリンティング・タグを見ることができる。 これを実現するために多くの作業が行われている。フィンガープリンティングを減らす努力の一環として、私はTor開発者が異なるTorビルド間のフィンガープリンティングのリグレッションを見つけられるよう、FP Centralというフィンガープリンティングのウェブサイトも開発した。
最後に、Tor Upliftプログラムの一環として、TBBに存在するより多くの修正がFirefoxに導入されつつある。
現状
ここ数年、ブラウザフィンガープリントの研究は大幅に増加し、この領域の多くの側面をカバーしている。ここでは学術界で行われた研究とフィンガープリンティングが産業界でどのように使用されているかを簡単に概観する。
学術研究
- フィンガープリンティングによる追跡は現実のものとなっているが、識別子に基づく様々な追跡スキームに取って代わることはできない。ウェブに接続された現代のデバイスの多様性を評価しようとする様々な研究が長年にわたって発表されている [1,2]。2018年に私が参加したある研究[3]は、一意性の割合が低い場合、非常に大規模な追跡は実現不可能かもしれないことを示し、私たちを驚かせた。いずれにせよ、これらの研究から得られた1つの明確な収穫は、次のとおりである:一部のブラウザベンダーがデバイス間の差異を可能な限り減らすために懸命に努力しているとしても、それは完璧なプロセスではない。ブラウザのフィンガープリント(またはその組み合わせ)に誰も持っていない値が1つでもあれば、あなたはまだ追跡される可能性があり、それがフィンガープリントに注意すべき理由である。今日、あなたのデバイスがインターネット上に存在する別のデバイスと同一であるという強力な保証はない。
- ウェブがより豊かになるにつれ、新しい API がブラウザに入り、新しいフィンガープリンティング技術が発見される。最も最近のテクニックには WebGL [4,5]、Web Audio [6]、拡張フィンガープリンティング [7,8]が含まれる。ユーザーを保護するためには、この分野の新しい進歩を注視し、発生しうる問題を修正することが重要である。
過去から学んだ教訓の1つは、BatteryStatus APIに関するものである。これは、開発者がエネルギー効率の良いアプリケーションを開発できるように、バッテリーの状態に関する情報を提供するために追加された。2011年の時点で草案が作成されていたが、研究者がこのAPIを悪用して短期識別子を作成できることを発見したのは2015年になってからだった[9,10]。結局のところ、これは、ブラウザに新しいAPIを導入する際には、非常に思慮深くなければならないということを思い起こさせるものだった。エンドユーザに導入される前に、隠されたフィンガープリントベクトルを可能な限り取り除くか軽減するために、深い分析が実施されなければならない。ウェブ仕様の作者にガイダンスを提供するため、W3C はフィンガープリンティングのリスクを考慮しながら API を設計する最善の方法に関する文書を書いた。

WebGL
図 4: http://uniquemachine.org/ でテストされた WebGL レンダリングの例
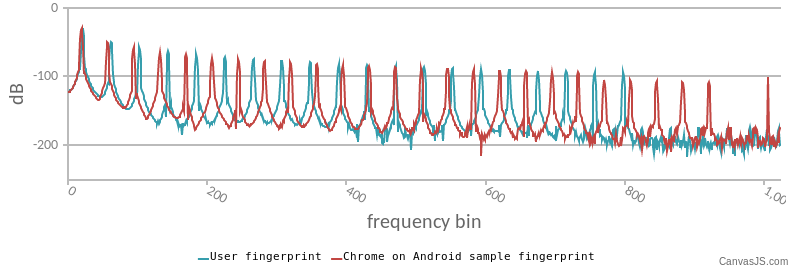
音声テスト
図 5: https://audiofingerprint.openwpm.com/ でテストされた音声フィンガープリントの例。
- 今日、ブラウザフィンガープリントをフィックスする究極のソリューションは存在しない。その起源はインターネットの始まりに根ざしているため、永久に修正できる単一のパッチは存在しない。そのため、防御を設計するのは難しい。長年にわたって多くのアプローチが試され、それぞれの長所と短所が評価されてきた。例えば、属性のブロック、ノイズの導入、値の修正、フィンガープリントの多様性の増加などがある。しかしながら、一つの重要な観察がなされたのは、特定の防御を持たない方が持つよりも良い場合があるということである。いくつかの解決策は設計またはコード化された方法のため、いくつかのフィンガープリントベクトルを取り除くが、収集されたフィンガープリントにいくつかのアーティファクトや不整合をもたらす。
例えば、送信前にフィンガープリントの値を変更するブラウザ拡張機能を想像してほしい。
開発者が navigator.platform の値をオーバーライドするのを忘れたという事実以外はすべて完璧に動作する。このため、ユーザーエージェントはブラウザが Windows で動作していると言うかもしれないが、プラットフォームはまだ Linux システムであることを示している。これは、現実には存在しないはずのフィンガープリントを作成し、そのようなものとして、ユーザーをオンラインでより目立つようにする。これはEckersley [1]が “Fingerprintable Privacy Enhancing Technologiesのパラドックス “と呼んだものである。オンライン・プライバシーを向上させたいがために、拡張機能をインストールし、結局は以前よりもさらに人目につくようになるのだ。
産業
- ブラウザフィンガープリントを使用しているウェブサイトを特定するには、単にプライバシーポリシーに目を向ければよい。たいていの場合、「フィンガープリンティング」という言葉を目にすることはないが、「サービスを向上させるためにデバイス固有の情報を収集しています」というような文章が書かれている。収集された属性の正確なリストはしばしば不正確であり、その情報の正確な使用は分析からセキュリティ、マーケティングや広告に至るまで非常に不透明な場合がある。
フィンガープリンティングを使ってウェブサイトを特定するもう一つの方法は、ブラウザで実行されるスクリプトを直接見ることだ。ここでの問題は、ユーザーエクスペリエンスを向上させるための善良なスクリプトとフィンガープリンティングのスクリプトを区別するのが難しいことである。例えば、あるサイトがあなたの画面解像度にアクセスする場合、それはHTML要素のサイズをあなたの画面に合わせるためなのか、それともあなたのデバイスのフィンガープリントを構築する最初のステップなのか。この2つの境界線は非常に薄く、フィンガープリントのスクリプトを正確に特定することは、まだ適切に研究されていない課題である。
- あまり知られていないフィンガープリンティングの用途の一つはbot検出である。ウェブサイトを保護するため、外部接続に関連するリスクを評価するオンラインサービスに依存する企業もある。以前は、接続をブロックするか受け入れるかの判断のほとんどは純粋に IP レピュテーションに基づいていた。現在、ブラウザのフィンガープリンティングは、改ざんを検出したり自動化の兆候を特定したりするために、さらに高度に使用されている。この目的でフィンガープリンティングを使用する企業の例としては、ThreatMetrix、Distil Networks、MaxMind、PerimeterX、DataDome などがある。
- 防御面では、より多くのブラウザベンダーがフィンガープリンティング保護をブラウザに直接追加している。このブログ記事で以前述べたように、TorとFirefoxは受動的フィンガープリンティングを制限し、能動的フィンガープリンティングのベクトルをブロックすることで、こうした取り組みの最前線にいる。
最初のリリース以来、Braveブラウザもそれに対する保護を内蔵している。
アップルは2018年にSafariに変更を加え、Chromeにも同様の変更を加える意向を2019年5月に発表した。
結論 この先にあるもの
ブラウザのフィンガープリンティングはここ数年で大きく発展した。この技術はブラウザ技術と密接に結びついているため、その進化を予測するのは難しいが、現在その使用方法は変化しつつある。かつて私たちが究極のトラッキング技術としてクッキーに取って代わると考えていたものは、単に真実ではない。最近の研究によれば、クッキーは一部のデバイスの識別には使えるものの、毎日ウェブを閲覧する大量のユーザーを追跡することはできない。その代わりに、フィンガープリンティングは現在セキュリティを向上させるために使われている。従来のIP分析を超える価値を見出す企業が増えている。彼らはフィンガープリントの内容を分析してボットや攻撃者を特定し、オンラインシステムやアカウントへの望ましくないアクセスをブロックしている。
フィンガープリントを取り巻く一つの大きな課題でまだ解決されていないのは、その使用の規制に関するものである。クッキーについては、クッキーが特定のウェブサイトによって設定されたかどうかをチェックするのは簡単である。誰でもブラウザの環境設定でクッキーの保存を確認できる。フィンガープリンティングの場合は話が違う。フィンガープリンティングの試みを検出する簡単な方法はなく、ブラウザにはその使用を完全にブロックするメカニズムもない。法的観点からは、これは非常に問題であり、規制当局はユーザーのプライバシーが尊重されるよう、企業と協力する新しい方法を見つける必要がある。
最後に、フィンガープリンティングは今後も残るのだろうか?少なくとも近い将来はそうだろう。この技術はウェブが始まって以来存在するメカニズムに根ざしているため、これを取り除くのは非常に複雑だ。ユーザー間の差異を可能な限り取り除くことは一つのことだ。デバイス固有の情報を完全に取り除くのは全く別のことだ。フィンガープリントが今後数年でどのように変化するかは時間が経ってみなければ分からないが、ウェブ開発の猛烈なペースがその過程で多くの驚きをもたらすことは間違いないため、その進化は注意深く見守る必要がある。
この記事を最後まで読んでくれてありがとう!このテーマをさらに深く掘り下げたい方は、最近オンラインで公開したこのテーマに関する調査 [11] を読んでいただきたい。もし万が一、Tor Browserで新しいフィンガープリントのベクトルを見つけたら、Torバグトラッカーでチケットを開くことを強く勧める!
Pierre Laperdrix
https://plaperdr.github.io/
ツイッター:https://twitter.com/RockPartridge
References
[1] P. Eckersley. “How unique is your web browser?”. In International Symposium on Privacy Enhancing Technologies Symposium (PETS’10). [[PDF]](https://panopticlick.eff.org/static/browser-uniqueness.pdf)
[2] P. Laperdrix, W. Rudametkin and B. Baudry. “Beauty and the Beast: Diverting Modern Web Browsers to Build Unique Browser Fingerprints”. In IEEE Symposium on Security and Privacy (S&P’16).
[[PDF]](https://hal.inria.fr/hal-01285470v2/document)
[3] A. Gómez-Boix, P. Laperdrix, and B. Baudry. “Hiding in the Crowd: an Analysis of the Effectiveness of Browser Fingerprinting at Large Scale”. In The Web Conference 2018 (WWW’18). [PDF]
[4] K. Mowery, and H. Shacham. “Pixel perfect: Fingerprinting canvas in HTML5”. In Web 2.0 Security & Privacy (W2SP’12). [PDF]
[5] Y. Cao, S. Li, and E. Wijmans. “(Cross-) Browser Fingerprinting via OS and Hardware Level Features”. In Network and Distributed System Security Symposium (NDSS’17). [PDF]
[6] S. Englehardt, and A. Narayanan. “Online tracking: A 1-million-site measurement and analysis”. In ACM SIGSAC Conference on Computer and Communications Security (CCS’16). [PDF]
[7] A. Sjösten, S. Van Acker, and A. Sabelfeld. “Discovering Browser Extensions via Web Accessible
Resources”. In ACM on Conference on Data and Application Security and Privacy (CODASPY’17). [PDF]
[8] O. Starov, and N. Nikiforakis. “XHOUND: Quantifying the Fingerprintability of Browser Extensions”. In IEEE Symposium on Security and Privacy (S&P’17). [PDF]
[9] Ł. Olejnik, G. Acar, C. Castelluccia, and C. Diaz. “The Leaking Battery”. In International Workshop on Data Privacy Management (DPM’15). [PDF]
[10] Ł. Olejnik, S. Englehardt, and A. Narayanan. “Battery Status Not Included: Assessing Privacy in
Web Standards”. In International Workshop on Privacy Engineering (IWPE’17). [PDF]
[11] P. Laperdrix, N. Bielova, B. Baudry, and G. Avoine. “Browser Fingerprinting: A survey”. [PDF – Preprint]
https://blog.torproject.org/browser-fingerprinting-introduction-and-challenges-ahead/
