Howdy! How can we help you?
(PI)世界中で最も使用されている基盤的IDシステムの分析をまとめる
以下は、Privacy Internationalのレポートの翻訳です。
PIは、世界中で最も使用されている基盤的IDシステムの分析をまとめた。
読む
投稿日
2021年10月26日
IDシステムのマッピング
世界各国の政府は、住民に対して国家デジタルIDシステムへの登録を義務付けるようになってきており、その必要性を、サービスへのアクセスの円滑化から国家安全保障、汚職との闘いに至るまで、さまざまな問題によって正当化している。政府エージェンシーによると、これは個人の「基盤となるID」、つまり誰かが誰であるかについての「単一の真実の情報源」を作ろうとする試みである。これらの ID システムは、政府によって運営されることもあれば、民間企業によって運営されることもあり、その両方が組み合わされて運営されることもある。
ID システムは、ますます広範な財やサービスにアクセスするための門番であり、その結果、 さまざまな人権の行使が制限される可能性がある。IDシステムの設計者や管理者は、人々が何にアクセスできるかをコントロールできるだけでなく、システムの使用を義務付けることもできる。
政府やその他の ID システム支持者は、ID システムの潜在的な利点を強調する一方で、そのようなシステムの導入から生じる潜在的な危害については、ほとんど注目されておらず、社会的な議論もなされていない。特に以下の点である。
- 排除 人々は、差別的な適用、技術的またはロジスティックな障壁、あるいは登録や照合ができ ないなどの理由で、ID を持っていない結果として、一部の公共サービスの利用から排除され る可能性がある。誰もが「読み取り可能な」指紋を持っているわけではないにもかかわらず、こうしたシス テムに登録するために、フィンガープリントのようなバイオメトリクス識別子の取得が義務づけ られることがある。人口の大部分が手作業に依存しており、人々の手や指先が擦れるため、フィンガープリント認証の失敗率は最大15%に上ると予想されているにもかかわらず、政府がこのような対策を進めているのを私たちは見てきた。同様に、誰かが利用することができないIDを持つことになった場合、排除が起こる可能性が高い(例えば、IDに割り当てられた性別マーカーが、自認する性別と異なる場合など)。
- 搾取 ID スキーム内での使用および処理を通じて、人々のデータが搾取されるうる。これは特に、「一意識別子」が導入される場合である。「一意識別子」とは、たとえば ID 番号のような一意の番号またはコードのことであり、これを通して政府お よび民間部門はさまざまなデータ・セットを結び付けることができる。この一意の識別子が政府や民間の複数のデータベースに普及することは、個人の「360度ビュー」を提供するリスクを意味する。その上、当初の合法的な目的を超えた目的でのさらなるデータ処理の懸念も生じる。
- 監視 IDシステムは、より広範な監視インフラの中で監視の道具として使用される可能性があり、多くの場合、私たちのプライバシーに対する不釣り合いかつ不必要な干渉につながり、他の人権侵害を可能にする。9.11以降、各国政府はIDシステムの導入を正当化しようとし、国家安全保障の名の下に、国境内や国境を越えて個人を無差別に追跡・追跡してきた。
このような危害は、文書またはクレデンシャルの発行およびそのために必要な情報から、デー タの保管および処理方法、さらには誰かが検証のためにクレデンシャルの提示を要求されたり、 要求されたりする時点に至るまで、ID システムに沿った複数の時点で発生する可能性がある。この事実を理解することで、政府は識別のための新しいテクノロジー・アプローチに 慎重になるはずである。
このような懸念があるにもかかわらず、政府が基盤となる ID システムの導入に踏み切る場合、彼らはそのようなシステムをどのように技術的かつ実際に展開するかという大きな疑問が残る。ナショナルID制度にはさまざまな形態がある。スマートカードを持つものもあればそうではない場合もあり、バイオメトリクスに頼るものもあれば頼らないものもある。出生登録にリンクしているものもあれば、そうでないものもある。有権者名簿にリンクしているものもあれば、そうでないものもある。全員に固有の番号を与えるものもあれば、そうでないものもある。高度なセキュリティー機能を持つものもあれば、導入する側がラミネート加工するものもある。
世界で最も使用されている基礎IDシステム:分析
このことを念頭に置いて、PIは世界中で最も使用されているIDシステムの分析をまとめた。この分析は、一般的に使用されている ID システムの特徴を読者が簡単に比較できるようにする目的で、公開され ている情報に基づいて、1 つの記事にまとめたものである。これは途中段階のものであり、時間の経過とともにさらに多くのシステムが追加される。調査結果の要約は以下の表にある。本稿執筆時点では、MOSIP、Adhaar、および e-Estonia の分析結果に基づいている:
ケーススタディ 分析されたIDシステム:MOSIP
ケーススタディ 分析されたIDシステム:Aadhaar
ケーススタディ 分析されたIDシステムの:e-Estonia
ケーススタディ 分析されたIDシステム:ペルーのDNIe
分析内容

要約表
私たちが調査公表した各個別分析について、
IDシステムの概要
これには、いつ、どこで、誰によって開発されたかという情報が含まれる。また、各特定のシステムの提唱者、代表者、資金提供者のリストも掲載しているため、意思決定者は特定のソリューションが誰によって推進されているのかを知ることができる。
この概要では、システムがオープンソースかプロプライエタリかについての情報も提供している。オープンソースシステムは、基本コードが公開されているという特徴がある。つまり、誰でもコードを調査、修正、配布することができ、ピアレビューやコミュニティによる制作に依存した分散型の方法で開発されている。政府が資金援助したソフトウェアがオープンソース化されることは重要であり、IDシステムの開発にオープンソースアプローチを採用することには、いくつかの利点がある:
- 実装が実際にどのように行われているかを誰でも見ることができるため、透明性が高まる、
- プロジェクトは、開発者、テスター、その他の貢献者の大規模なコミュニティに開かれており、彼らは常にフィードバックを提供し、新機能で積極的に貢献し、バグを修正することができる、
- その上、オープンソースのソリューションの方が安価でより柔軟であることが多い。
- また、オープンソースのソリューションは、一人の作者や企業ではなくコミュニティによって開発されているため、プロプライエタリな代替製品よりも長寿命であることが多い。
悪意のある攻撃者が時間をかけて脆弱性やコードを悪用する方法を探すことができるため、コードベースをオープンソースにすることはリスクの源になるという意見もあるかもしれない。現実には、一般の人々の目からコードを遠ざけておいても、このような事態を防ぐことはできない。
現在分析されているIDシステムのうち、2つがオープンソース・ソフトウェアに依存している:
- MOSIPは完全にオープンソースであり、そのコードはすべて公開されている。
- e-Estoniaのサービスは、オープンソースのデータ交換レイヤーであるX-Roadに依存している。これに加え、エストニア政府は今年初め、すべての政府ソフトウェアをこのリポジトリで一般公開することを決定した。
- Aadhaarは、ロプライエタリなテクノロジーに依拠しており、インド政府にもUIDAI(Unique Identification Authority of India)にも属さない独自のテクノロジーに依存しているため、事実上どのように運用されているのかを知ることができないという意味で、システムを「ブラックボックス」にしている。
インフラ構成についての洞察
認証属性と個人データは適切に保護される必要がある。暗号化とは、権限のないユーザーがアクセスできないようにデータを暗号化するプロセスである。名前、生年月日といった人々の個人情報を保存し、扱うだけでなく、世界中のいくつかの基幹 ID システムでは、生体認証データの利用が増加している。
このような機微で一意に識別できる個人データを使用する場合、最も厳重なセキュリ ティ保護措置を講じることが義務付けられるべきである。暗号化は、不要な第三者からデータを保護し、ユーザーに信頼できる認証プロセスを提供し、ユーザー、サーバー、クライアントアプリなどのエンティティが本人であるかどうかを判断する際に信頼性を提供するために極めて重要である。
私たちは通常、情報が見つからないか、使用されているものがきちんとしておらず明らかに危険なもの(時代遅れの暗号化プロトコルを使用している、あるいは暗号化をまったく使用していないなど)でない限り、いかなる近代的なソフトウェアにおいて、強力な暗号の使用が前提されるべきであり、かかるものとして、私たちはその実装については議論しないつもりだ。
ユーザーデータは中央集権的な方法で保存されるのか、それとも分散的な方法で保存されるのか?
電子データベースは、ID データを格納、参照、検証、および認証するための好ましい選択肢であ る。これらのデータベースは、国および実装されたソ リューションに応じて、中央リポジトリまたは分散システムとして存在することができる。
物理的 V 論理的(非)中央集権化
(地理的に分散した複数の物理コンピュータにデータベースを分散させる(「シャーディングsharding」として知られるプロセスを通じて、データベースの異なる部分を異なる場所に保持するか、または完全に同一のものとして複製され たデータベースを複数のコンピュータに分散させる)か、または何らかの形式の API(Application Programming Interface)を使用して相互作用する別々の(できれば地理的に 分散した)データベースに論理的に分離したデータを保持する。
論理的な分散化は設計上の決定事項であるが、物理的な分散化は、操作するデータベースを物理的にユーザーの近くに「移動」させることで、アクセスを高速化できる可能性もあるとともに、単一障害点を減らす(排除しようとす る)ために、どのようなアットスケールシステムにおいても期待されるものである。
重複排除の処理方法に関する洞察
ID 重複排除は、システム内で自然人と一意な「ID」との 1:1 マッチングを試みるために使用する 手続きである。最終的な目標は、一人の人間が 2 つの「ID」を持つケース、あるいは 1 つの「ID」 を複数の人間が共有するケースをなくすことである。
システムによっては、純粋に人口統計データに基づいて重複排除を試みるものもあれば、デー タベースにすでに格納されている生体情報と比較しようとするものもある。
誤検出
例えばAadhaarの場合、UIDAIはバイオメトリクス重複排除に関する概念実証レポートを発表した。このレポートの中でUIDAIは、以下のような理由により、時折偽陽性が発生することが予想されるとしている:
- バイオメトリクス収集機器の欠陥
- バイオメトリクスを正しい「ユニーク」プロファイルに割り当てる際の人為的ミス
- 一人が別の名前で二度登録
- 2人の人が偶然同じバイオメトリクスを持つ
このコンセプトは、UIDAI(Unique Identification Authority of India)が0.0025%の偽陽性識別率を目指している4万人のサンプルに基づいている。ここでいう誤認とは、バイオメトリック・システムが個人と他人のバイオメトリック識別子を誤って照合することを意味する。これは多くないように思えるかもしれないが、サンプルサイズをインドの人口13億8000万人に拡大すると、バイオメトリクスを本人確認の目的で使用する場合、一人当たり1万7000件以上の誤検出を解決しなければならないことになる。
これは実際には、バイオメトリクスだけでは13億8,000万人のなかの一人であることを証明できないことを意味する。むしろ、全人口の中で、その1つのバイオメトリクス識別子を持つ17,000人のうちの1人であることを証明できるだけである。このことは、生体情報の重複排除を行う際、現実には偶然の誤検出よりもはるかに多くの誤検出を扱うことになり、UIDAIのCIDR(Central Identities Data Repository)にあるすべてのIDが生体的に一意であると主張することは不可能であることを示している。これらの数字を得るために使用された簡単な数学の分析結果は、Aadhaarに関する私たちの調査で見ることができる。
各システムに関わる原則
デジタルIDシステムの設計と配備におけるテクノロジーの選択には、様々な政治的動機が示されているということができ、それは最も深いレベルで社会がどのように運営されるかに影響を与える。大規模な社会技術システムの設計、開発、ガバナンスは、社会的・政治的集団の間で異なる公共秩序と権力の固定化を確立する可能性がある。
このことを念頭に置き、各IDシステムの技術的なインフラ構成に関する情報を提示するほか、開発者が公表しているエンゲージメント原則や統治原則が存在する場合は、それについても掘り下げていく。このような外部条件やセーフガードに関するガイドラインは、そのツールを使用する際の悪用や搾取のリスクを最小化するために、開発者がどのようであるべきだと考えているかを示すものになっている。
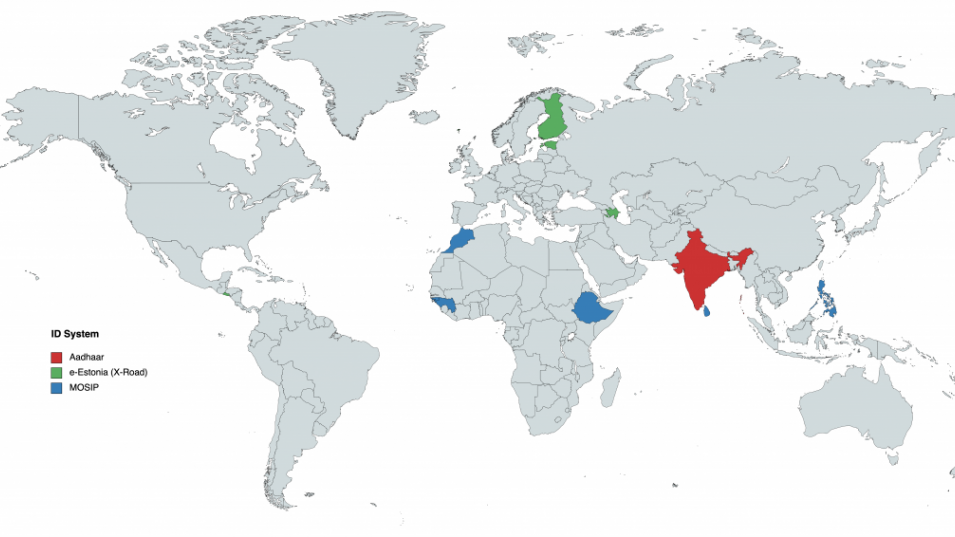
特定の ID システムが導入されている、または将来導入されることが確実な国
Aadhaar
インド(2009年)MOSIP:
モロッコ(2018年)
フィリピン(2019年)
ギニア(2021年)
エチオピア(2020年)
スリランカ(近日署名する予定)e-エストニア(X-Road):
エストニア(2001年)
フィンランド(2017年)
アゼルバイジャン(2018年)
フェロー諸島(2016年)
エルサルバドル(2017年)調査対象ID制度が使用されている国における誤用のレポート例
私たちの調査では、「安全」、「包括的」、「プライバシー・フレンドリー」を謳うシステムもあるにもかかわらず、分析したすべてのシステムで不正使用のレポート例を発見した。
例えば、インドのAadhaarは、長年にわたって、大規模なデータ流出、給付金へのアクセスからの除外、さらには重複排除をめぐる問題など、悪用に関する無数のレポートがあった。このリストだけでも、2017年2月から2018年5月までの間に40件近くの漏洩があった。流出したデータは、Aadhaar番号や人口統計情報に限らない。妊娠に関するデータ、人々の宗教やカースト、さらには銀行の詳細情報といった機密データが、Aadhaar番号とともに流出したケースもある。インド政府はまた、無数の社会保護制度を利用するために、Aadhaarへの登録を必須条件としている。この措置は、多くの人々にとってアクセスに厚い障壁を作り出し、食糧配給を受ける機会を減らすことにつながり、全国で何人もの餓死者を出している。その上、インド政府とインド一意識別局(UIDAI)は、プライバシーの懸念や、インド市民が識別プロセスにと繋がるたびに最大17,000件の誤認識が発生する可能性があるという試験的プロジェクトのサンプルテストの結果を無視してきた。この組織的な失敗により、一人の人間がどういうわけか2つの異なる “ユニークな “Aadhaar番号を取得してしまうケースが発生している。
MOSIPはモロッコでも導入されており、言語による排除が懸念されている。モロッコの国家安全保障総局は、2020年に新世代のIDカードを導入すると発表したが、法律案によると、カードはアラビア語(国の2つの公用語のうちの1つ)とフランス語(外国の非憲法言語)のみになり、第2の公用語であるタマサイト語は除外される。これは、モロッコの公的生活に徐々にタマザイト語を取り入れ、国民IDカードを含む管理文書でアラビア語と並んでタマザイト語の使用を奨励することを目的とした規制に真っ向から反するものである。
e-EstoniaやX-Roadに基づくIDシステムが導入されている国では、今日に至るまで同様の不正使用に関するレポートはない。
方法論
各システムについて提示された情報は、すべて一般に入手可能な情報源から収集した。前述したように、分析対象となったシステムのいくつかはオープンソースであり、使用されているソースコードへの一般公開を含め、透明性のレベルを高めている。これにより、当該システムに関するテクノロジーに関する記述を誰でも確認することができるようになり、これは非常に貴重な機能であることを強調しなければならない。その反対に、IDシステムの設計者や所有者が公開した文書に基づいて調査した「ブラックボックス」システムもある。このような場合、システムが文書に記述されたとおりに動作するかどうかを一般人が検証することは不可能となる。したがって、一般人の知識は信頼に基づくものとなり、一般人の消費に適した情報として選ばれたものに限定される。
https://privacyinternational.org/long-read/4656/digital-national-id-systems-ways-shapes-and-forms
