Howdy! How can we help you?
(EFF)オンライントラッキング会社があなたのオンライン行動のほとんどを知る方法(そして、ソーシャルネットワークが彼らを助けるためにしていること
テクニカル分析:Peter Eckersleys 2009年9月21日
この記事は、今日のウェブ上のユーザートラッキングに関するシリーズのパート2です。パート1はこちら、パート3はこちらでご覧いただけます。
サードパーティの広告会社やトラッキング会社は、現代のウェブではいたるところに存在しています。ウェブページにアクセスすると、そこには小さな画像や目に見えないJavaScriptが含まれている可能性が高く、それらはユーザーの閲覧傾向を追跡・記録することを唯一の目的として存在しています。この種のトラッキングは、何十もの異なる企業によって行われています。この記事では、このようなトラッキングがどのように行われているか、また、ソーシャルネットワークサイトのアカウントから得られるデータと組み合わせて、お客様のオンライン活動を広範囲に渡って特定するためのプロファイルを構築しているかについて見ていきたいと思います。
第三者がウェブ上のあなたの行動を知る方法。
米国最大のオンライン求人サイトであるCareerBuilder.comにアクセスして仕事を検索したところ、CareerBuilderには10もの異なるトラッキングドメインのJavaScriptコードが含まれていました。Rubicon Project、AdSonar、Advertising.com、Tacoda.net(いずれもAOLの広告部門)、Quantcast、Pulse 360、Undertone、AdBureau(Microsoft Advertisingの一部)、Traffic Marketplace、DoubleClick(Googleの広告部門)です。また、CareerBuilderには、他のドメインからのトラッキングスクリプトやJavaScript以外のウェブバグが含まれていることも確認されています。オンラインで仕事を探すときに、その事実が聞いたこともない何十社もの企業に流されないことを望むのには、それ相当な理由があるわけですが、ここではまさにそれが起こっているのです。
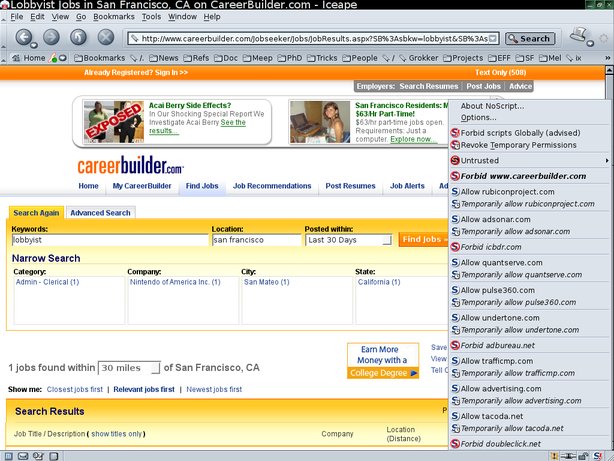
CareerBuilderの検索結果には、10のサードパーティのトラッキングサイトのコンテンツが含まれています。
(このスクリーンショットでは、ページにコードが埋め込まれているサードパーティを識別するためにNoScriptが使用されています)
これらのトラッキング会社は、複数の異なるウェブサイトでユーザーを追跡することができ、ウェブを閲覧するユーザーを効果的に追跡することができます。これらの企業は、クッキー、削除が困難な「スーパークッキー」、またはその他の手段を使用して、あなたが新しいページを閲覧した際の記録を、あなたの過去数分、数ヶ月、数年に渡って閲覧したすべてのページの記録と関連づけます。ウェブ上の大部分のサイトにサードパーティ製のウェブバグやトラッキングスクリプトが広く存在しているため、これらの企業は、私たちがウェブブラウザを使って行うほとんどの行動の長期的なプロファイルを構築することができます。
私たちを追跡することはできても、私たちが誰であるかを知ることはできません。
トラッキング会社が私たちの閲覧履歴をどれだけ知っているかを考えると、これらの会社が私たちのことも知っているかどうかを問うてみる価値はあるでしょう。残念ながら、その答えは、少なくともソーシャル・ネットワーキング・サイトを利用している私たちにとっては「イエス」だといえそうです。
Balachander KrishnamurthyとCraig Willsによる最近の研究論文によると、Facebook、LinkedIn、MySpaceなどのソーシャル・ネットワーキング・サイトは、トラッキング企業がすでに保持している記録に、あなたの名前、友人リスト、その他のプロフィール情報を簡単に追加する方法を提供しているといいます。
この論文の主なテーマは、ソーシャル・ネットワーキング・サイトにログインすると、ソーシャル・ネットワークには広告やトラッキング・コードが含まれていて、第三者がソーシャル・ネットワーク上のどのアカウントが自分のものかを知ることができるというものです。そして、あなたのプロフィールページにアクセスして、その内容を記録し、自分のファイルに追加することができるのです。この論文で調査された12のソーシャルネットワークのうち、個人を特定できる情報を第三者に漏らさなかったのはOrkutだけでした。
SNSがこのデータをどのようにリークするかについては、技術的に興味深い点があります。意図せずに流出する場合もあれば、巧妙で密かな反プライバシーエンジニアリングが働いている場合もあります。
ソーシャルネットワークからサードパーティのトラッキング企業へのデータ流出経路
サードパーティのトラッキング企業が、SNSのどのアカウントがあなたのものであるかを知る最もはっきりした方法は、HTTP Referrerヘッダを介したものです。ソーシャルネットワーキングサイトの典型的なURLには、ユーザー名やユーザーID番号が含まれており、第三者もこれを見ることができます[1]。
2つ目の方法は、サードパーティのコンテンツのURL/URIパラメータを使って個人情報を流出させる方法です。ここでは論文から匿名化された例を紹介します。
GET /track/?…&fb_sig_time=1236041837.3573&
fb_sig_user=123456789&…
ホスト: adtracker.socialmedia.com
Referer: http://apps.facebook.com/kick_ass/…
(このリクエストでは、FacebookアプリがユーザーのFacebookユーザーIDとサインイン時間をadtracker.socialmedia.comに送信しています)
3つ目の最も驚くべき個人情報の流出方法は、同一生成元ポリシーthe same origin policyに違反して、サードパーティのトラッキングサーバをホストサイトのドメイン名でエイリアス化し、サードパーティがホストサイトのクッキーを見ることができるようにすることです。以下は同論文の例です。
GET /st?ad_type=iframe&age=29&gender=M&e=&zip=11301&…
ホスト: ad.hi5.com
Referer: http://www.hi5.com/friend/profile/displaySameProfile.do?userid=123456789
Cookieを使用しています。LoginInfo=M_AD_MI_MS|US_0_11301; Userid=123456789;Email=jdoe@email.com;
(ad.hi5.comは実際にはad.yieldmanager.comであり、リファラー、URIパラメーター、hi5.comのクッキーを介して、同一生成元ポリシーでは許可されないさまざまな個人情報を受け取っています – つまり、3つの漏洩方法の一例です)
自分を守るためにはどうすればいいか?
残念ながら、クッキーやJavaScriptに依存した最新のウェブサイトやソーシャルネットワークサイトを利用しながら、同時にトラッキングを回避する簡単な方法はありません。これらのトラッキングメカニズムから実質的に守られるためには、以下のようなことが必要になります。
1.「ブラウザを閉じるまでの間だけクッキーを保存する」、「すべてのクッキーを手動で承認する」など、ブラウザに適したクッキーポリシーを選択する。
2. フラッシュ・クッキーやその他すべての種類の「スーパー・クッキー」を無効にする。
3. Firefoxの拡張機能であるRequestPolicyとNoScriptを使って、サードパーティのサイトがあなたのページにコンテンツを掲載したり、ブラウザでコードを実行したりするのをそれぞれ制御する。これらのツールは非常に効果的ですが、使いこなすのが難しいことに注意してください。JavaScriptに依存している多くのサイトが正しく動作するには、ホワイトリストに登録する必要があります。
4. Targeted Advertising Cookie Opt-Outプラグインを使用する。このプラグインは、クッキーの受け入れを要求するオプトアウト機能を持つサードパーティのトラッカーから、自動的にあなたを除外します。すべてのサードパーティがオプトアウトを提供しているわけではありません。また、サードパーティの中には、「オプトアウト」を「ターゲット広告を表示しない」という意味ではなく、「オンラインでの私の行動を追跡しない」という意味で解釈しているところもありますので注意してください。
5. また、ブラウザのプライバシーを最大限に保護したい場合は、TorButton経由でTorを使用し、IPアドレスやその他のブラウザの特性を隠すこともできます。
残念ながら、上記のステップの多くは非常に難しく、大多数のインターネットユーザーは、聞いたことのない会社、何の関係もない会社、最も私的な思考や読書習慣を信頼することを選択しない会社など、何十もの会社に追跡され続けることになると私たちは危惧しています。
この問題を解決するのは容易ではありません。技術的な面では、このようなトラッキングは、ウェブがインタラクティブなハイパーテキストシステムとして設計されていることに加え、多くのウェブサイトが広告主による訪問者のトラッキングを喜んでサポートしているという事実に起因しています。ブラウザーを変更してトラッキングを困難にすることは可能ですが、そもそもインタラクティブなハイパーテキストの利点を損なうことなくこれを実現するには、細心の注意と巧妙な設計が必要になるでしょう。そのための正しい方法を誰かが見つけたかどうかも定かではありません。
法的な面では、米国の現行のプライバシー体制が機能していないことは明らかです。行動追跡企業はプライバシーポリシーの細則に好きなことを書くことができますが、CareerBuilderやその他のウェブサイトの訪問者のうち、ポリシーを読むことはおろか、トラッキング企業が存在することに気づく人はほとんどいないでしょう。そろそろ、自分のプライバシーがサイト訪問の対価の一部になっていることを、人々が実際に知ることができるような法的ルールを作るべきだと思います。
注
1.微妙な点として、第三者がプロフィールがあなたのものなのか他人のものなのかを見分けられないことがあります。しかし、これを回避する方法はいくつかあります。たとえば、第三者は、プロフィールの編集に関連するURLなど、友人があなたのプロフィールに対して行うことができないその他の活動を探すことができます。
出典:https://www.eff.org/deeplinks/2009/09/online-trackers-and-social-networks
